模块化设计思想
模块化设计思想,是将一个复杂的问题分解为多个模块,每个模块独立,分工处理他们所面对的单一问题,以降低复杂度,提升开发效率;
Wikipedia 对分工的解释
分工指个人、公司、国家或地区都负责自己所擅长的工作。由于工人的工作效率提高,产量及产品质素也相继提高,人们的生活水平也因而得以改善,分工的发展是人类社会经济进步的重要里程碑。
提高效率的因素
早在18世纪,亚当·斯密在其著作《国富论》中就已观察到分工对于手工业生产效率的提高。他将效率提高的原因归结于三点:
- 熟练程度的增加。当一个工人单纯地重复同一道工序时,其对这道工序的熟练程度会大幅增加。表现为产量和质量的提高。
- 如果没有分工,由一道工序转为另一道工序时会损失时间,而分工避免了这中间的损失。
- 由于对于工序的了解和熟练度的增加,更有效率的机械和工具被发明出来,从而提高了产量。
现代社会对于的产业链的分工更为细化和专业化,从原料到成品的生产更有效率。
虽然现实世界分工分块的概念,与编程概念有所不同,但其原理是相通的,也是我们在整个研发、产品团队不断重构,完善所期望达成的目标。
模块化思想有什么特点
- 将一个产品看成一系列功能模块的组合
- 按照功能模块划分来进行代码的编写
-
最终将各个模块组合在一块
-
大到可以是一个集成模块 用户模块、商品模块、登录、注册…
-
小到可以是一个方法
-
各个模块之间是相互独立的
-
即开发时互不干扰
-
由各个模块又可以组成新的集成模块
模块化开发有什么好处
-
更好的代码复用
-
提高开发效率,缩短开发时间
-
降低耦合度
-
减少 bug 的定位时间
-
降低发布风险
-
避免全局污染,命名冲突
-
文件依赖
-
协同开发
什么是函数式编程
函数式编程,是一种编程范式,简而言之可以理解为:函数接收相同的参数总会返回相同的值;
(不会因外部变量而导致返回不同结果,不会修改输入参数的引用值,也叫做"纯函数")
函数式编程主要有以下几个特点:
Functions As First-class Citizens (头等公民)
函数可以作为别的函数的参数、函数的返回值,赋值给变量或存储在数据结构中。
No Side Effects (无副作用)
在计算机科学中,函数副作用( Side Effect )指当调用函数时,除了返回函数值之外,还对外部作用域产生附加的影响,例如修改全局变量(函数外的变量)或修改参数。而严格的函数式编程是要求函数必须没有副作用,这意味着影响函数返回值的唯一因素就是它的参数
No Changing-state (无状态改变)
在函数式编程中,函数就是基础元素,可以完成几乎所有的操作,哪怕是最简单的计算,也是用函数来完成的,而我们平时在其他类型中所理解的变量( 可修改,往往用来保存状态 )在函数式编程中,是不可修改的
Currying (柯里化)
在计算机科学中,柯里化( Currying )是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
Concurrency (并发性)
在函数式编程中,由于没有副作用,函数不会影响或者依赖于全局状态,所以程序是支持并发( Concurrency )执行的。因为不需要采用锁机制,所以完全不用担心死锁或者并发竞争的情况会发生。
Lazy Evaluation (惰性求值)
又称惰性计算、懒惰求值,是一个计算机编程中的一个概念,它的目的是要最小化计算机要做的工作。
immutable JS 的引入
考虑到 Immutable 的接入需要所有研发人员对Immutable的理解保持一致,才有可能实现Immutable接入后所起到的优化作用。在此希望大家能理解 Immutable 所解决的问题。
原生js引用类型的可变性
|
1 2 3 4 5 6 7 8 9 10 11 12 |
// 场景一 var obj = {a:1, b:{c:2}}; func(obj); console.log(obj) //输出什么?? // 场景二 var obj = ={a:1}; var obj2 = obj; obj2.a = 2; console.log(obj.a); // 2 console.log(obj2.a); // 2 |
考虑下以上两种场景
- 当引用类型变量的引用地址,被其他变量持有时,对变量节点数据修改是有副作用,且不可逆的;
- 通常这类问题的解决方案是通过浅拷贝或者深拷贝复制一个新对象,从而使得新对象与旧对象引用地址不同,但性能大打折扣;
- 为了解决这种问题,出现了immutable对象,每次修改immutable对象都会
创建一个新的不可变对象,而原有的对象不会改变;
Persistent Data Structure (持久化数据结构)
持久化数据结构是指一个数据,在被修改时,仍然能够保持修改前的状态,从本质来说,这种数据类型就是 [immutable] 不可变类型,并非是将数据存储到某个介质。
Structural Sharing (结构共享)
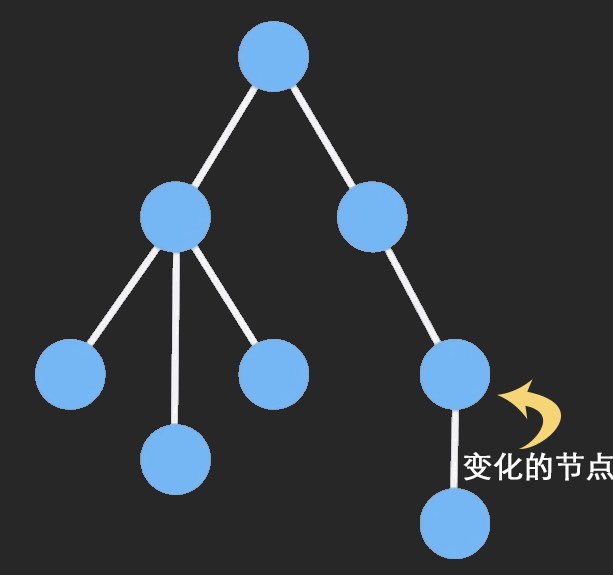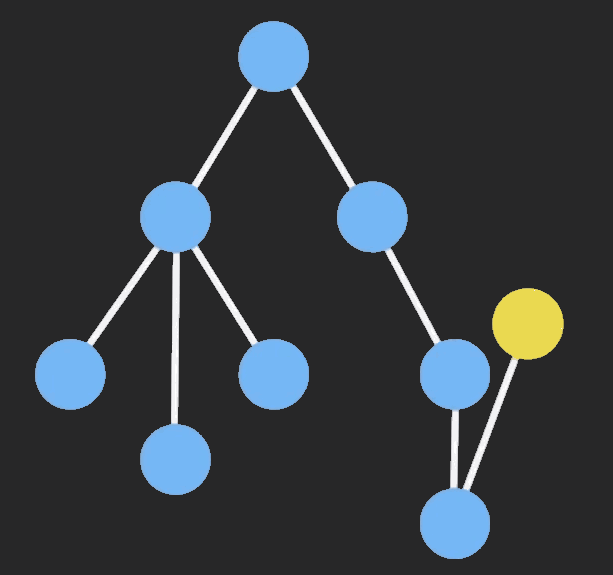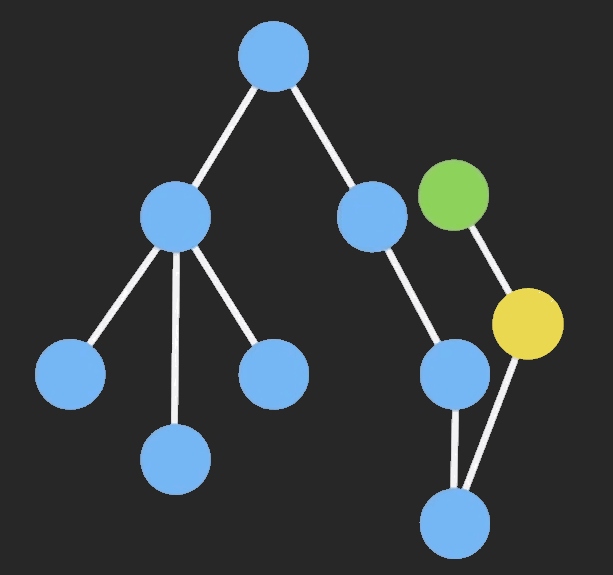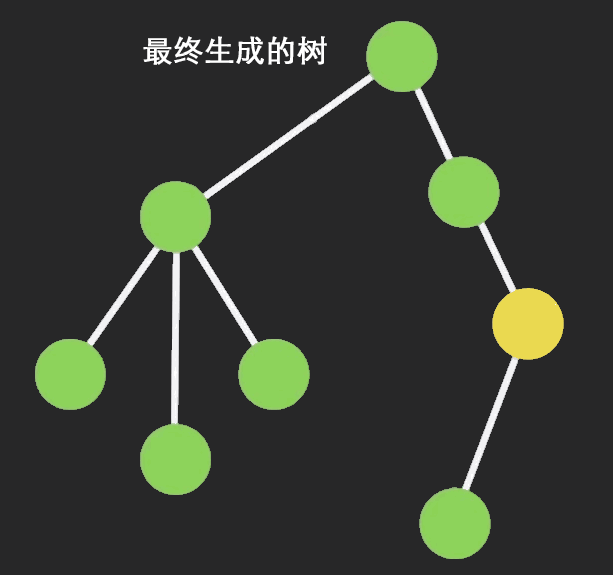
Immutable对象进行操作的时候,ImmutableJS会只clone该节点以及它的祖先节点,其他保持不变,这样可以共享相同的部分,大大提高性能。
Support Lazy Operation (延迟操作)
延迟操作,同"延迟加载"的语义相似,是指当程序运行时,在这里是指(取值时)才执行Sequence序列操作。(用一个Demo说明)
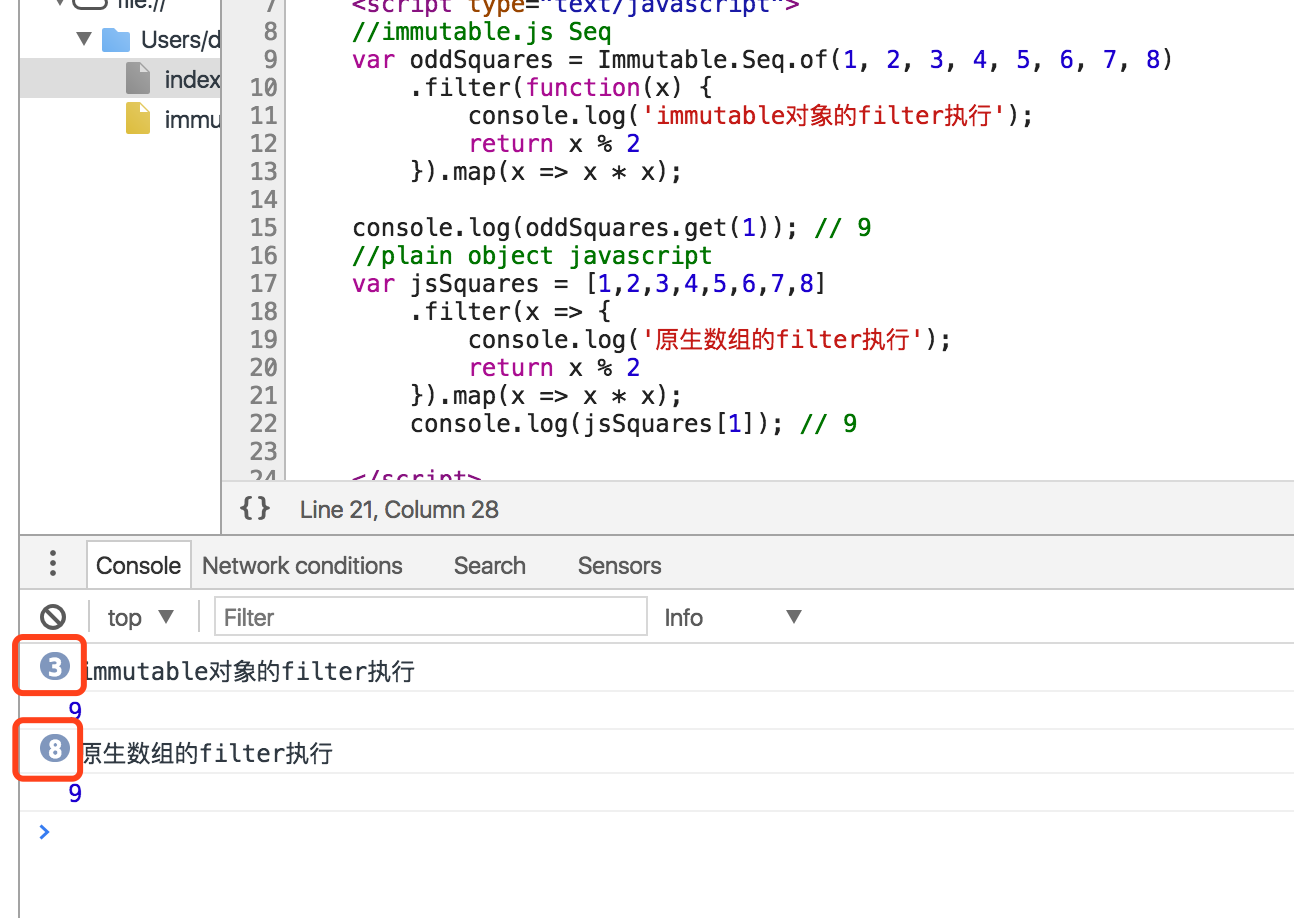
其实Demo的原理就是,用seq创建的对象,其实代码块没有被执行,只是被声明了,代码在get(1)的时候才会实际被执行。
- 非延迟操作的执行顺序
|
1 2 3 4 5 6 |
filter([1,2,3,4,5,6,7,8]) => [1,3,5,7] map([1,3,5,7]) => [1,9,25,49] squares = [1,9,25,49] squares[1] = 9 return 9 |
- 延迟操作的执行顺序是:
|
1 2 3 4 5 6 7 |
squares.get(1) filter(1).map(1*1) = 1 //index:squares[0] filter(2) //null filter(3).map(3*3) = 9 //index:squares[1] return 9 |
Immutable 的优缺点
优点:
- 降低mutable带来的复杂度
-
节省内存
-
历史追溯性(时间旅行):时间旅行指的是,每时每刻的值都被保留了,想回退到哪一步只要简单的将数据取出就行,想一下如果现在页面有个撤销的操作,撤销前的数据被保留了,只需要取出就行,这个特性在redux或者flux中特别有用。
-
拥抱函数式编程:immutable本来就是函数式编程的概念,纯函数式编程的特点就是,只要输入一致,输出必然一致,相比于面向对象,这样开发组件和调试更方便
缺点:
-
需要重新学习api
-
资源包大小增加(源码5000行左右)
-
容易与原生对象混淆:由于api与原生不同,混用的话容易用混淆。